Semantic Segmentation using Fully Convolutional Networks over the years
Introduction
Semantic Segmentation of an image is to assign each pixel in the input image a semantic class in order to get a pixel-wise dense classification. While semantic segmentation / scene parsing has been a part of the computer vision community since 2007, a major breakthrough came when fully convolutional neural networks were first used by Long et al. 2014 to perform end-to-end segmentation of natural images.


Figure: Example of semantic segmentation (Left) generated by FCN-8s overlayed on the input image (Right)
The FCN-8s architecture achieved a 20% relative improvement to 62.2% mean IU on Pascal VOC 2012 dataset. This architecture was a baseline for semantic segmentation on top of which several newer and better architectures were developed.
Fully Convolutional Networks (FCNs) are being used for semantic segmentation of natural images, for multi-modal medical image analysis and multispectral satellite image segmentation. Very similar to deep classification networks like AlexNet, VGG, ResNet etc., there is also a large variety of deep architectures that perform semantic segmentation.
I summarize networks like FCN, SegNet, U-Net, FC-DenseNet, E-Net & Link-Net, RefineNet, PSPNet, Mask R-CNN, and some semi-supervised approaches like DecoupledNet and GAN-SS here and provide reference PyTorch and Keras implementations for a number of them.
Network Architectures
A general semantic segmentation architecture can be broadly thought of as an encoder network followed by a decoder network. The encoder is usually a pre-trained classification network like VGG/ResNet followed by a decoder network. The decoder network/mechanism is mostly where these architectures differ. The task of the decoder is to semantically project the discriminative features (lower resolution) learnt by the encoder onto the pixel space (higher resolution) to get a dense classification.
Available implementations:
- PyTorch: meetps/pytorch-semseg
A more formal summarization of semantic segmentation (including recurrent style networks) can also be found here.
Fully Convolution Networks (FCNs)
We adapt contemporary classification networks (AlexNet, VGG net, GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations.
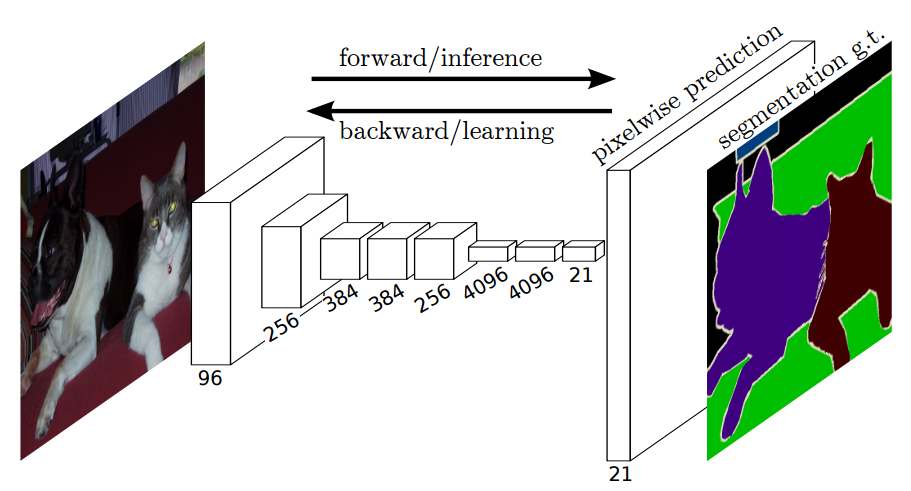
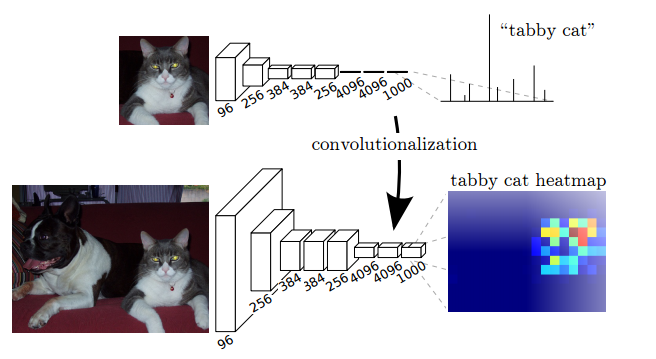
Key features:
- Features are merged from different stages in the encoder which vary in coarseness of semantic information.
- The upsampling of learned low resolution semantic feature maps is done using deconvolutions initialized with bilinear interpolation filters.
- Excellent example for knowledge transfer from modern classifier networks like VGG16, AlexNet to perform semantic segmentation.
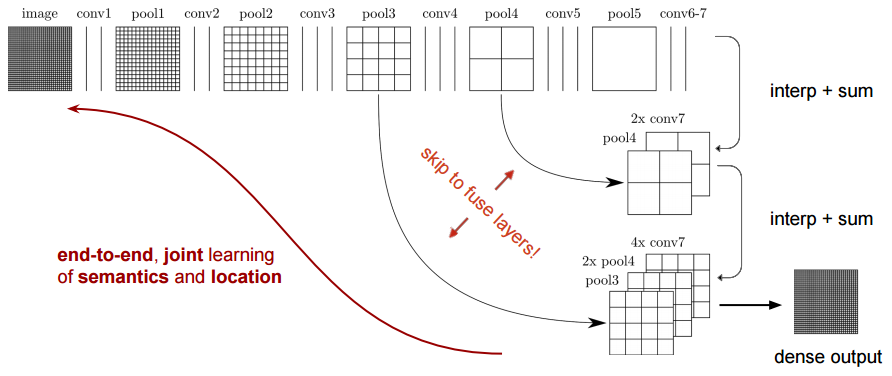
The fully connected layers (fc6, fc7) of classification networks like VGG16 were converted to fully convolutional layers. This produces a class presence heatmap in low resolution, which then is upsampled using bilinearly initialized deconvolutions and at each stage of upsampling further refined by fusing features from coarser but higher resolution feature maps from lower layers in VGG16 (conv4 and conv3).
In conventional classification CNNs, pooling is used to increase the field of view and at the same time reduce the feature map resolution. While this works best for classification, for semantic segmentation, any sort of operation that reduces spatial resolution is detrimental as spatial information is lost. Most architectures differ mainly in the mechanism employed in the decoder to recover the information lost in the encoder.
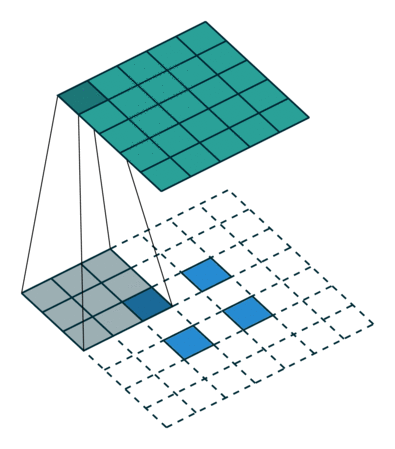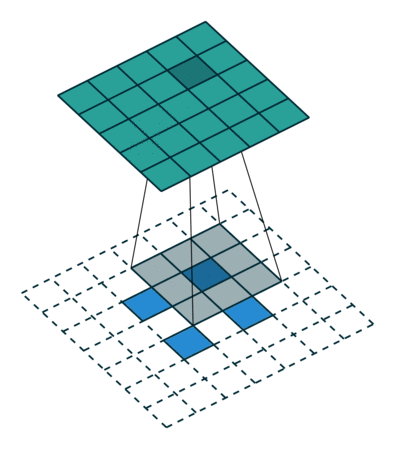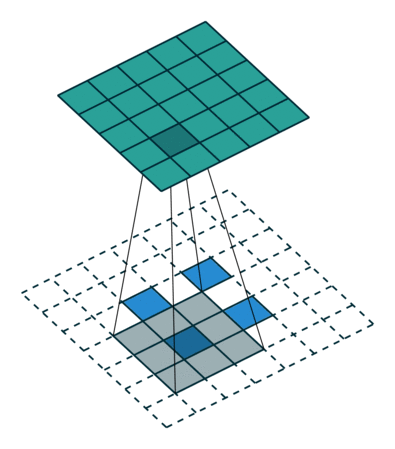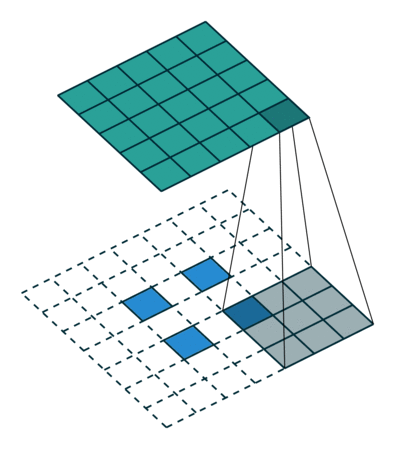
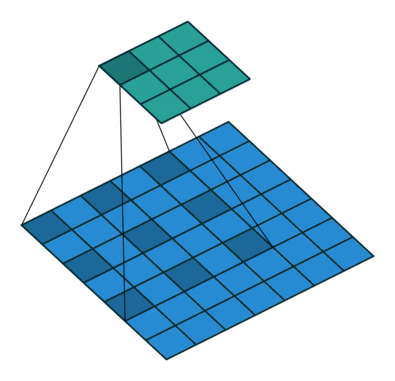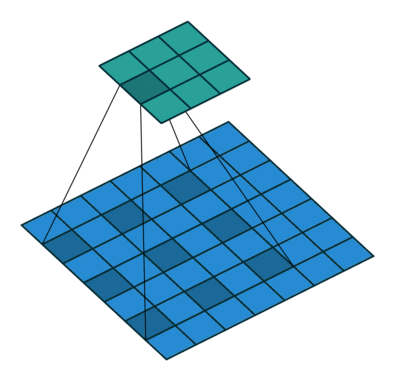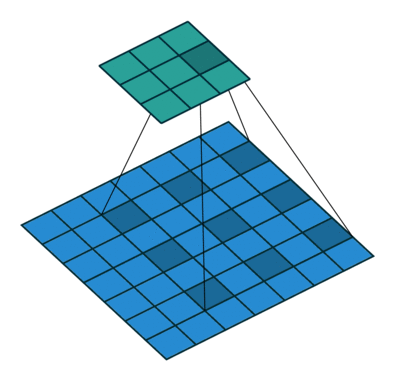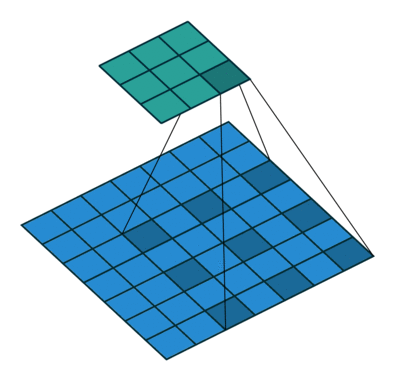
Other important aspects include the mechanism used for feature upsampling using learned deconvolutions, or partially avoiding the reduction of resolution altogether in the encoder using dilated convolutions at the cost of computation.
SegNet
The novelty of SegNet lies in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample.
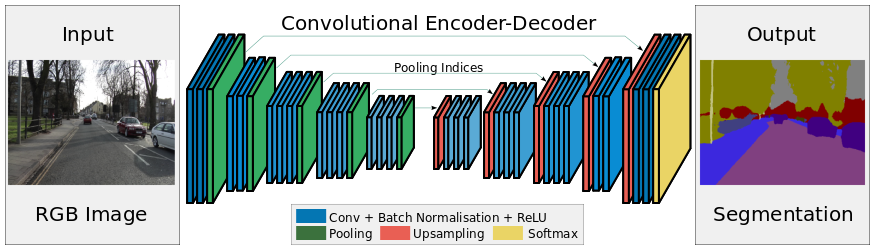
Key features:
- SegNet uses unpooling to upsample feature maps in decoder to keep high frequency details intact in the segmentation.
- This encoder doesn't use the fully connected layers and hence is a lightweight network with fewer parameters.
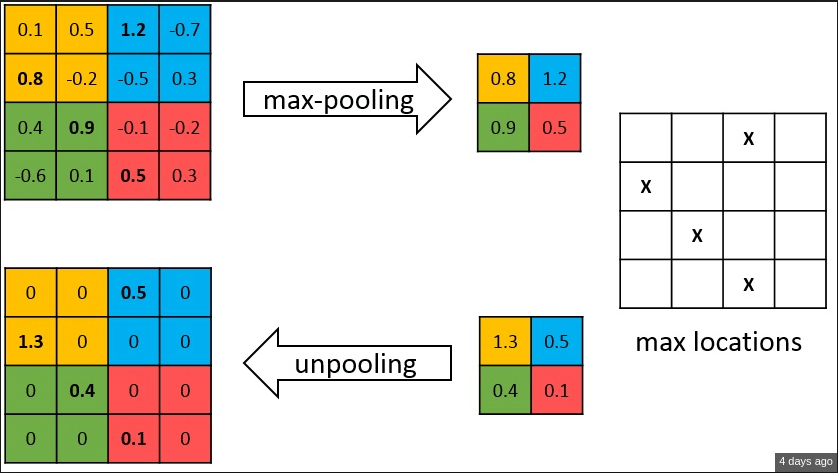
As shown above, the indices at each max-pooling layer in encoder are stored and later used to upsample the corresponding feature map in the decoder by unpooling it using those stored indices. While this helps keep the high-frequency information intact, it also misses neighboring information when unpooling from low-resolution feature maps.
U-Net
The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method on the ISBI challenge.
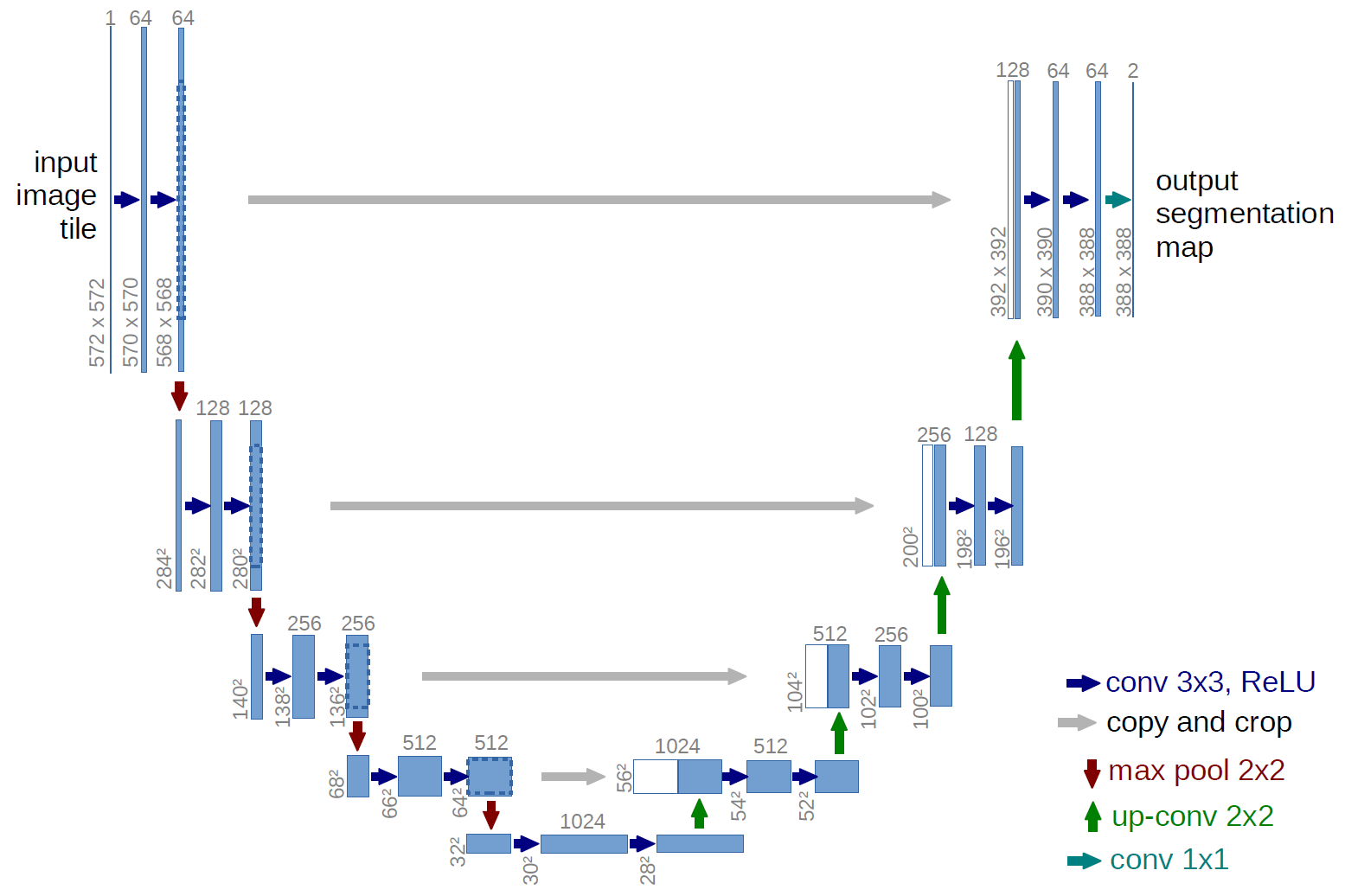
- U-Net simply concatenates the encoder feature maps to upsampled feature maps from the decoder at every stage to form a ladder-like structure.
- The architecture by its skip
concatenationconnections allows the decoder at each stage to learn back relevant features that are lost when pooled in the encoder.
U-Net achieved state-of-the-art results on EM Stacks dataset which contained only 30 densely annotated medical images, and was later extended to a 3D version 3D-U-Net. It has found use in several fields including satellite image segmentation and medical image analysis.
Fully Convolutional DenseNet
We extend DenseNets to deal with the problem of semantic segmentation. We achieve state-of-the-art results on urban scene benchmark datasets such as CamVid and Gatech, without any further post-processing module nor pretraining.
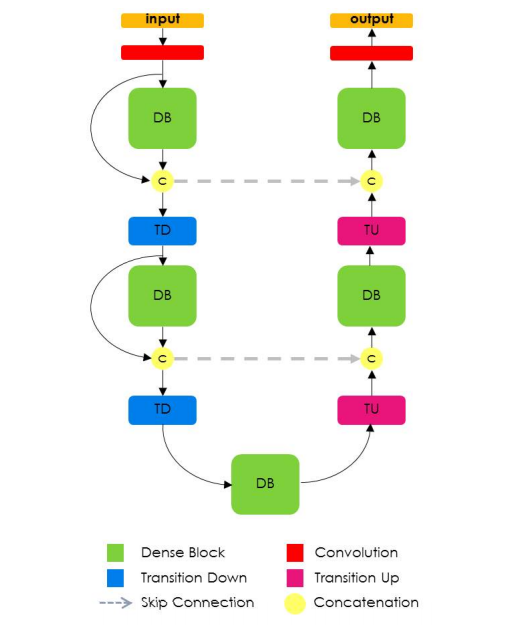
Fully Convolutional DenseNet uses a DenseNet as its base encoder and, similar to U-Net, concatenates features from encoder and decoder at each rung.
E-Net and Link-Net
ENet is up to 18x faster, requires 75x less FLOPs, has 79x less parameters, and provides similar or better accuracy to existing models. LinkNet can process an input image of resolution 1280x720 on TX1 and Titan X at 2 fps and 19 fps respectively.
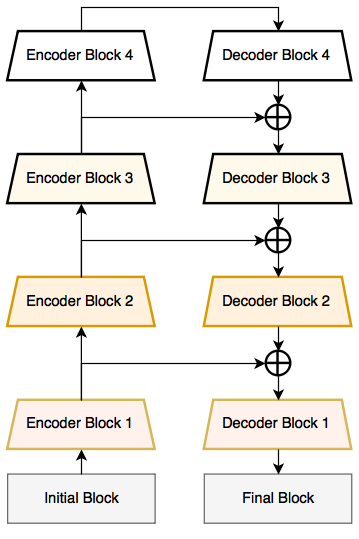
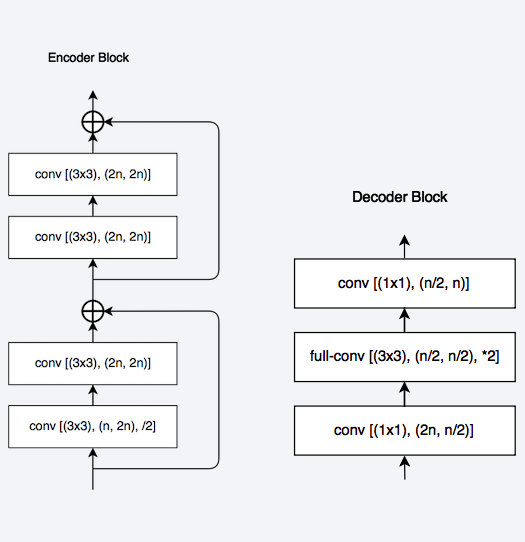
The LinkNet Architecture resembles a ladder network architecture where feature maps from the encoder (laterals) are summed with the upsampled feature maps from the decoder (verticals). The decoder block consists of considerably fewer parameters due to its channel reduction scheme.
Mask R-CNN
Mask R-CNN extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. It is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps.
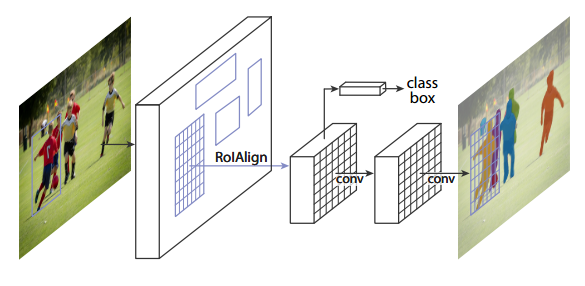
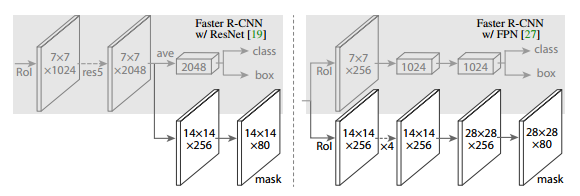
Key features:
- Faster R-CNN with an auxiliary branch to perform semantic segmentation.
- The RoIPool operation has been modified to RoIAlign which avoids spatial quantization for feature extraction.
- Mask R-CNN combined with Feature Pyramid Networks achieves state-of-the-art results on MS COCO dataset.
PSPNet
We exploit the capability of global context information by different-region-based context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet).
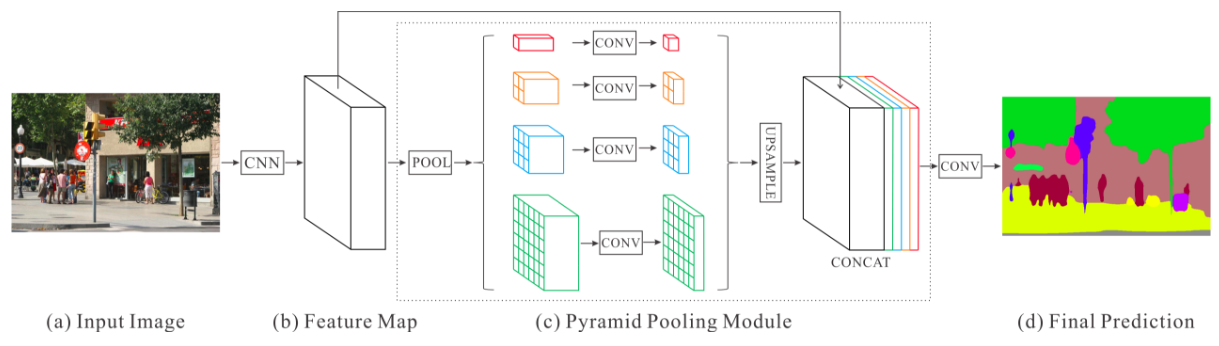
Key features:
- PSPNet modifies the base ResNet architecture by incorporating dilated convolutions and features are processed at the same resolution throughout the encoder.
- Introduction of auxiliary loss at intermediate layers of the ResNet.
- Spatial Pyramid Pooling at the top of the modified ResNet encoder to aggregate global context.
The PSPNet architecture is currently the state-of-the-art in CityScapes, ADE20K and Pascal VOC 2012. A full visualization of the network can be found here.
RefineNet
RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections.
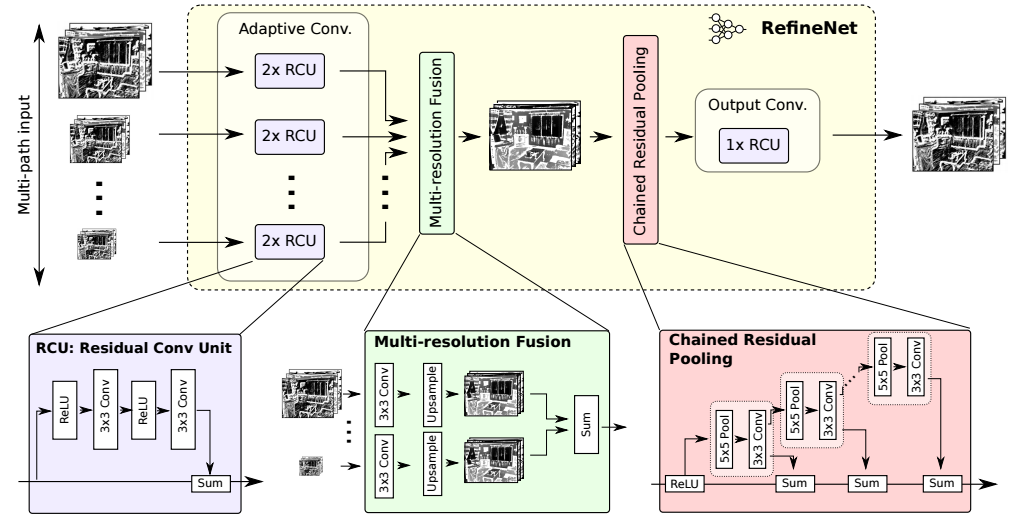
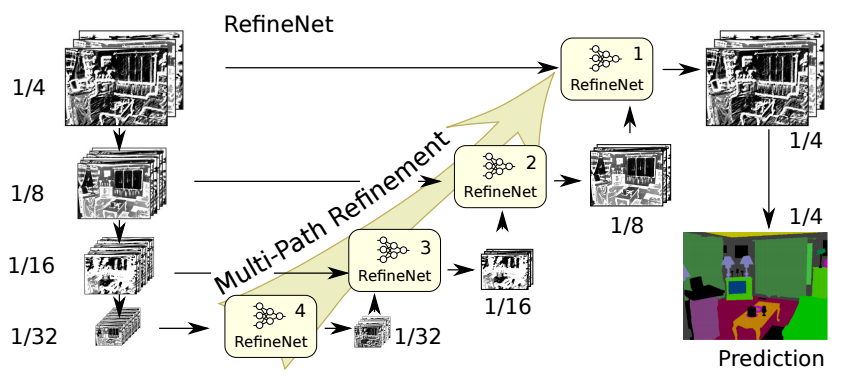
Key features:
- Uses inputs at multiple resolutions, fuses the extracted features and passes them to the next stage.
- Introduces Chained Residual Pooling which can capture background context from a large image region.
- All feature fusion is done using
sum(ResNet style) to allow end-to-end training. - Uses vanilla ResNet style residual layers without expensive dilated convolutions.
G-FRNet
Gated Feedback Refinement Network (G-FRNet), an end-to-end deep learning framework for dense labeling tasks. We introduce gate units that control the information passed forward in order to filter out ambiguity.
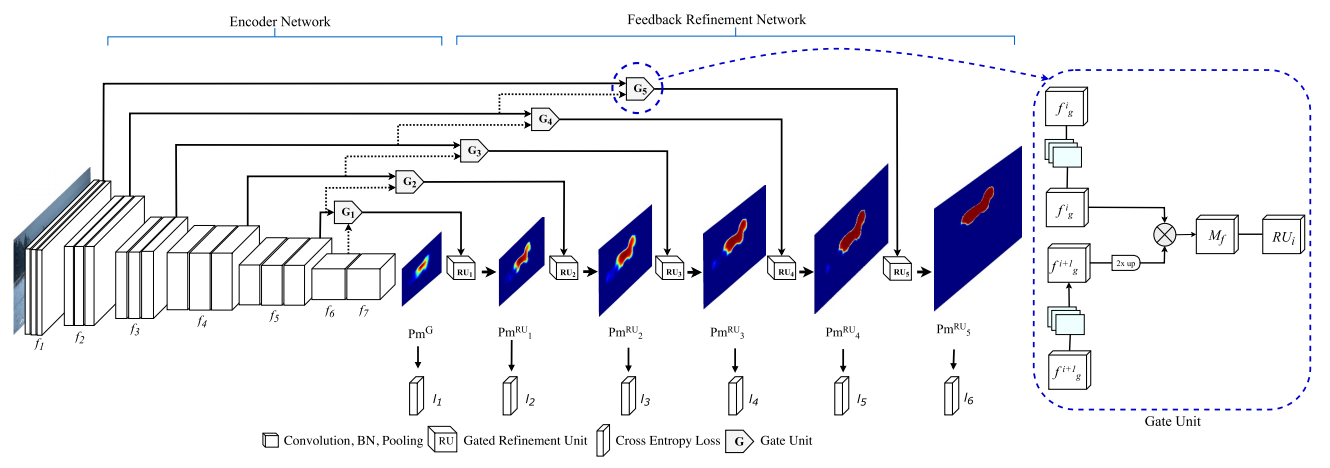
Most architectures rely on simple feature passing using concatenation, unpooling or sum. However, information that flows from higher resolution layers may or may not be of utility for segmentation. Gating the information flow from encoder to decoder using Gated Refinement Feedback Units can assist the decoder in resolving ambiguities. The experiments in this paper reveal that ResNet is a far superior encoder than VGG16 for semantic segmentation.
Semi-Supervised Semantic Segmentation
DecoupledNet
Our algorithm decouples classification and segmentation, and learns a separate network for each task. Labels associated with an image are identified by classification network, and binary segmentation is subsequently performed for each identified label.
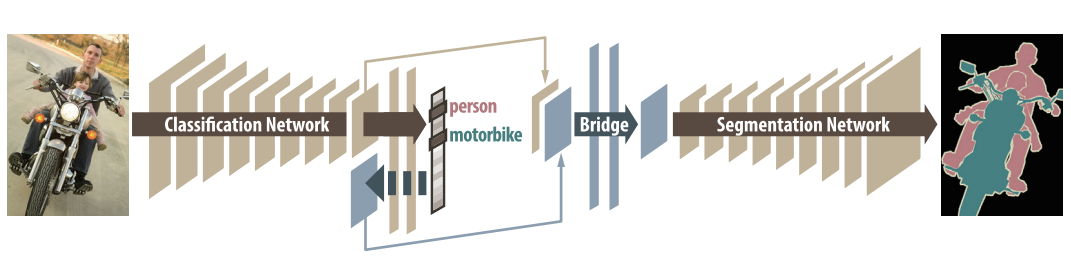
- Decouples the classification and the segmentation tasks, enabling pre-trained classification networks to be plugged and played.
- Bridge Layers between the classification and segmentation networks produce class-salient feature maps.
- This method needs
kpasses to segmentkclasses in an image.
GAN Based Approaches
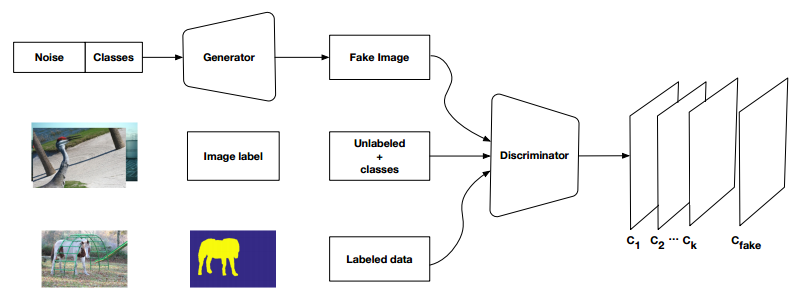
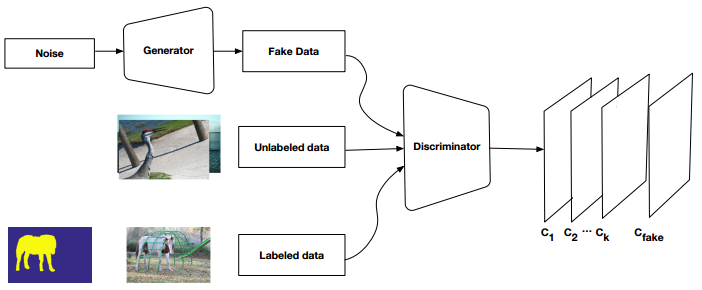
Datasets
| Dataset | Training | Testing | Classes |
|---|---|---|---|
| CamVid | 468 | 233 | 11 |
| Pascal VOC 2012 | 9,963 | 1,447 | 20 |
| NYUDv2 | 795 | 645 | 40 |
| Cityscapes | 2,975 | 500 | 19 |
| Sun-RGBD | 10,355 | 2,860 | 37 |
| MS COCO '15 | 80,000 | 40,000 | 80 |
| ADE20K | 20,210 | 2,000 | 150 |
Results
Sample semantic segmentation maps generated by FCN-8s (trained using the pytorch-semseg repository) overlaid on input images from Pascal VOC validation set:












In case this doesn't work for you, or if there is a mistake/typo, please open an issue in the repo.