Semantic Segmentation using Fully Convolutional Networks over the years
Semantic Segmentation
Introduction
Semantic Segmentation of an image is to assign each pixel in the input image a semantic class in order to get a pixel-wise dense classification. While semantic segmentation / scene parsing has been a part of the computer vision community since 2007, but much like other areas in computer vision, major breakthrough came when fully convolutional neural networks were first used by 2014 Long et. al. to perform end-to-end segmentation of natural images.


Figure : Example of semantic segmentation (Left) generated by FCN-8s ( trained using pytorch-semseg repository) overlayed on the input image (Right)
The FCN-8s architecture put forth achieved a 20% relative improvement to 62.2% mean IU on Pascal VOC 2012 dataset. This architecture was in my opinion a baseline for semantic segmentation on top of which several newer and better architectures were developed.
Fully Convolutional Networks (FCNs) are being used for semantic segmentation of natural images, for multi-modal medical image analysis and multispectral satellite image segmentation. Very similar to deep classification networks like AlexNet, VGG, ResNet etc. there is also a large variety of deep architectures that perform semantic segmentation.
I summarize networks like FCN, SegNet, U-Net, FC-Densenet E-Net & Link-Net, RefineNet, PSPNet, Mask-RCNN, and some semi-supervised approaches like DecoupledNet and GAN-SS here and provide reference PyTorch and Keras (in progress) implementations for a number of them. In the last part of the post I summarize some popular datasets and visualize a few results with the trained networks.
Network Architectures
A general semantic segmentation architecture can be broadly thought of as an encoder network followed by a decoder network. The encoder is usually is a pre-trained classification network like VGG/ResNet followed by a decoder network. The decoder network/mechanism is mostly where these architectures differ. The task of the decoder is to semantically project the discriminative features (lower resolution) learnt by the encoder onto the pixel space (higher resolution) to get a dense classification.
Unlike classification where the end result of the very deep network ( i.e. the class presence probability) is the only important thing, semantic segmentation not only requires discrimination at pixel level but also a mechanism to project the discriminative features learnt at different stages of the encoder onto the pixel space. Different architectures employ different mechanisms (skip connections, pyramid pooling etc) as a part of the decoding mechanism.
A number of above architectures and loaders for datasets is available in PyTorch at:
- PyTorch: meetps/pytorch-semseg
A more formal summarization of semantic segmentation ( including recurrent style networks ) can also be found here
Fully Convolution Networks (FCNs)
| CVPR 2015 | Fully Convolutional Networks for Semantic Segmentation | Arxiv |
We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
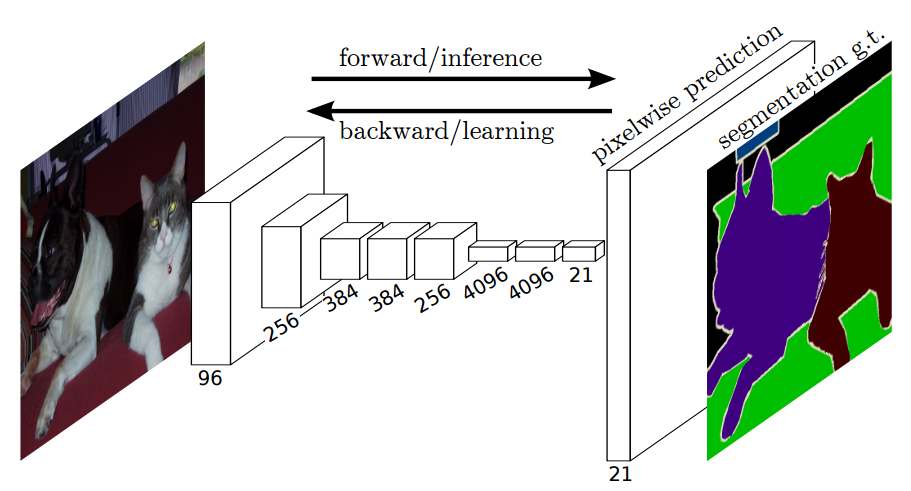
Figure : The FCN end-to-end dense prediction pipeline.
A few key features of networks of this type are:
- The features are merged from different stages in the encoder which vary in coarseness of semantic information.
- The upsampling of learned low resolution semantic feature maps is done using deconvolutions which are initialized with billinear interpolation filters.
- Excellent example for knowledge transfer from modern classifier networks like VGG16, Alexnet to perform semantic segmentation
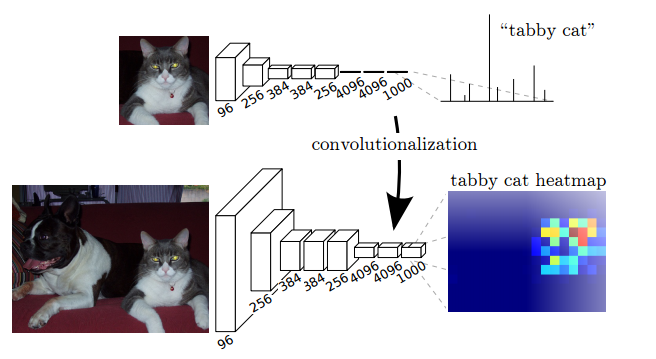
Figure : Transforming fully connected layers into convolutions enables a classification network to output a class heatmap.
The fully connected layers (fc6, fc7) of classification networks like VGG16 were converted to fully convolutional layers and as shown in the figure above, it produces a class presence heatmap in low resolution, which then is upsampled using billinearly initialized deconvolutions and at each stage of upsampling further refined by fusing (simple addition) features from coarser but higher resolution feature maps from lower layers in the VGG 16 (conv4 and conv3) . A more detailed netscope-style visualization of the network can be found in at here
In conventional classification CNNs, pooling is used to increase the field of view and at the same time reduce the feature map resolution. While this works best for classification as the end goal is to just find the presence of a particular class, while the spatial location of the object is not of relevance. Thus pooling is introduced after each convolution block, to enable the succeeding block to extract more abstract, class-sailent features from the pooled features.
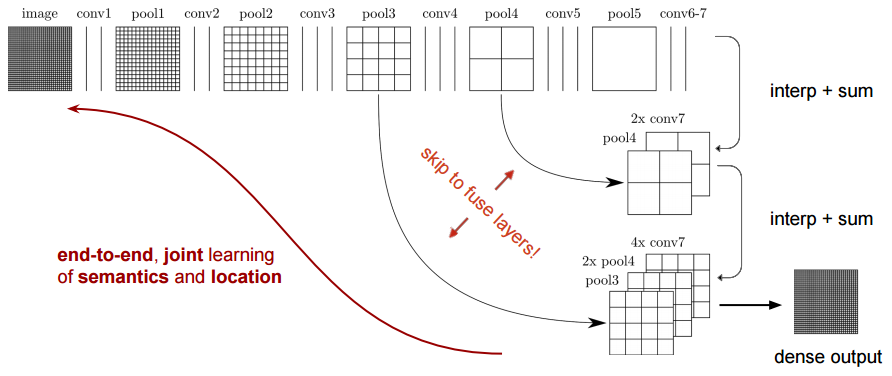
Figure : The FCN-32s Architecture
On the other hand any sort of operation - pooling or strided convolutions is deterimental to for semantic segmentation as spatial information is lost. Most of the architectures listed below mainly differ in the mechanism employed by them in the decoder to recover the information lost while reducing the resolution in the encoder. As seen above, FCN-8s fused features from different coarseness (conv3, conv4 and fc7) to refine the segmentation using spatial information from different resolutions at different stages from the encoder.
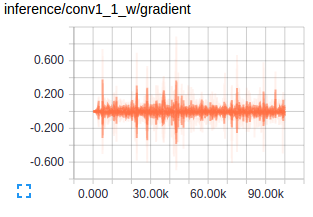
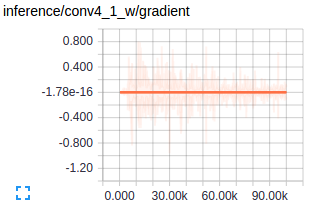
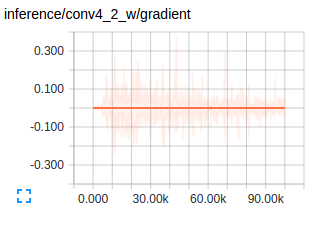
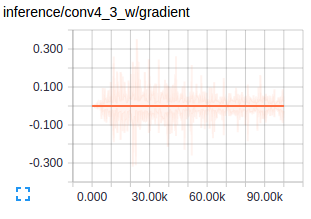
Figure : Gradients at conv layers when training FCNs Source
The first conv layers captures low level geometric information and since this entrirely dataset dependent you notice the gradients adjusting the first layer weights to accustom the model to the dataset. Deeper conv layers from VGG have very small gradients flowing as the higher level semantic concepts captured here are good enough for segmentation. This is what amazes me about how well transfer learning works.
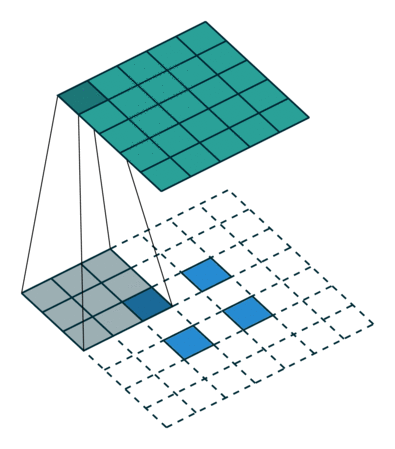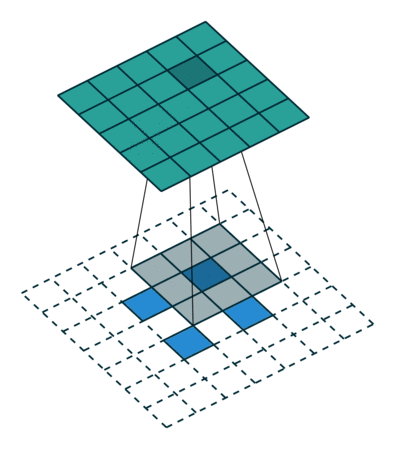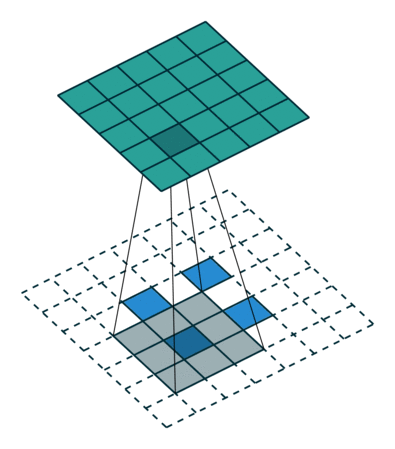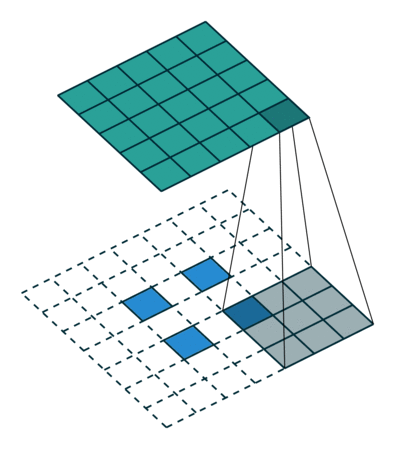
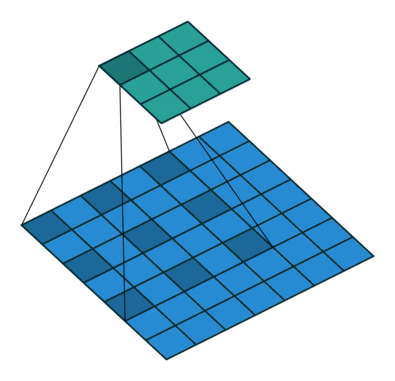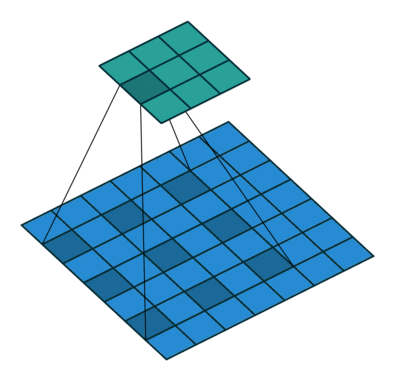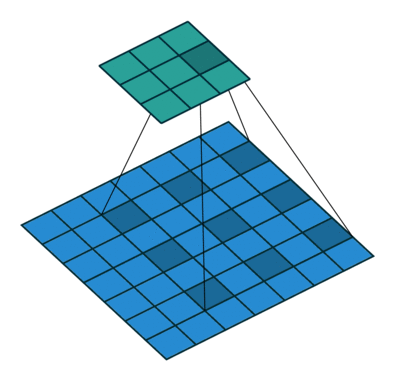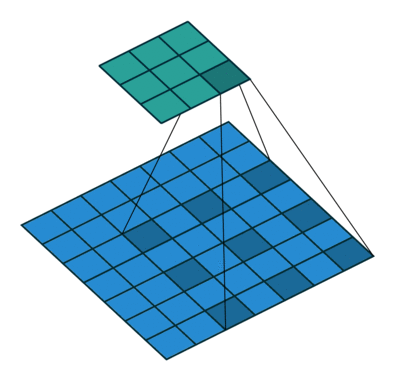
Left : Deconvolution (Transposed Convolution) and Right : Dilated (Atrous) Convolution Source
Other important aspect for a semantic segmentation architecture is the mechanism used for feature upsampling the low-resolution segmentation maps to input image resolution using learned deconvolutions or partially avoid the reduction of resolution altogether in the encoder using dilated convolutions at the cost of computation. Dilated convolutions are very expensive, even on modern GPUs. This post on distill.pub explains in a much more detail about deconvolutions.
| 2015 | SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation | Arxiv |
The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN and also with the well known DeepLab-LargeFOV, DeconvNet architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance.
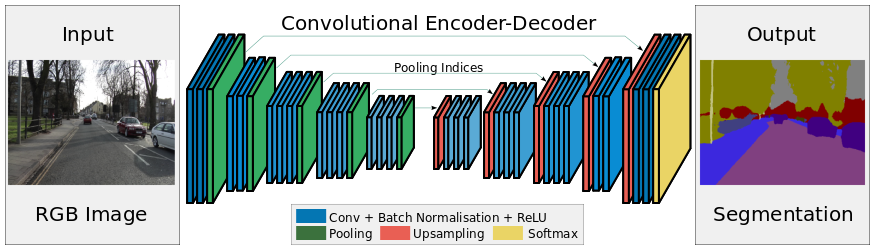
Figure : The SegNet Architecture
A few key features of networks of this type are:
- SegNet uses unpooling to upsample feature maps in decoder to use and keep high frequency details intact in the segmentation.
- This encoder doesn’t use the fully connected layers (by convolutionizing them as FCN) and hence is lightweight network lesser parameters.
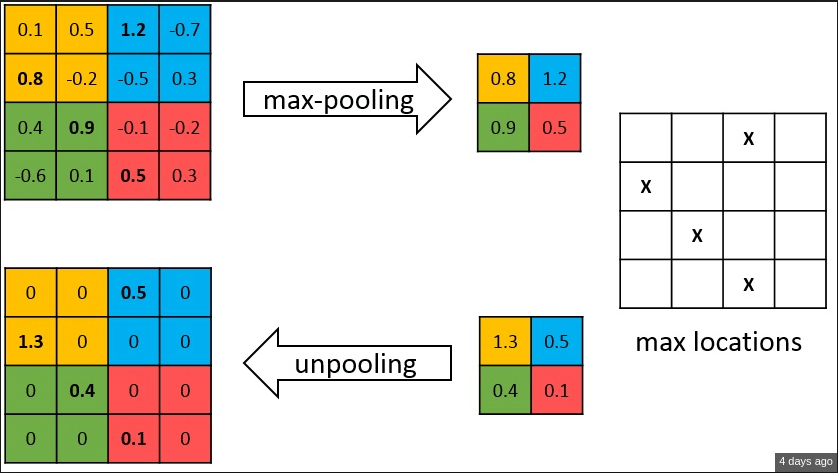
Figure : Max Unpooling
As shown in the above image, the indices at each max-pooling layer in encoder are stored and later used to upsample the correspoing feature map in the decoder by unpooling it using those stored indices. While this helps keep the high-frequency information intact, it also misses neighbouring information when unpooling from low-resolution feature maps.
| MICCAI 2015 | U-Net: Convolutional Networks for Biomedical Image Segmentation | Arxiv |
The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU
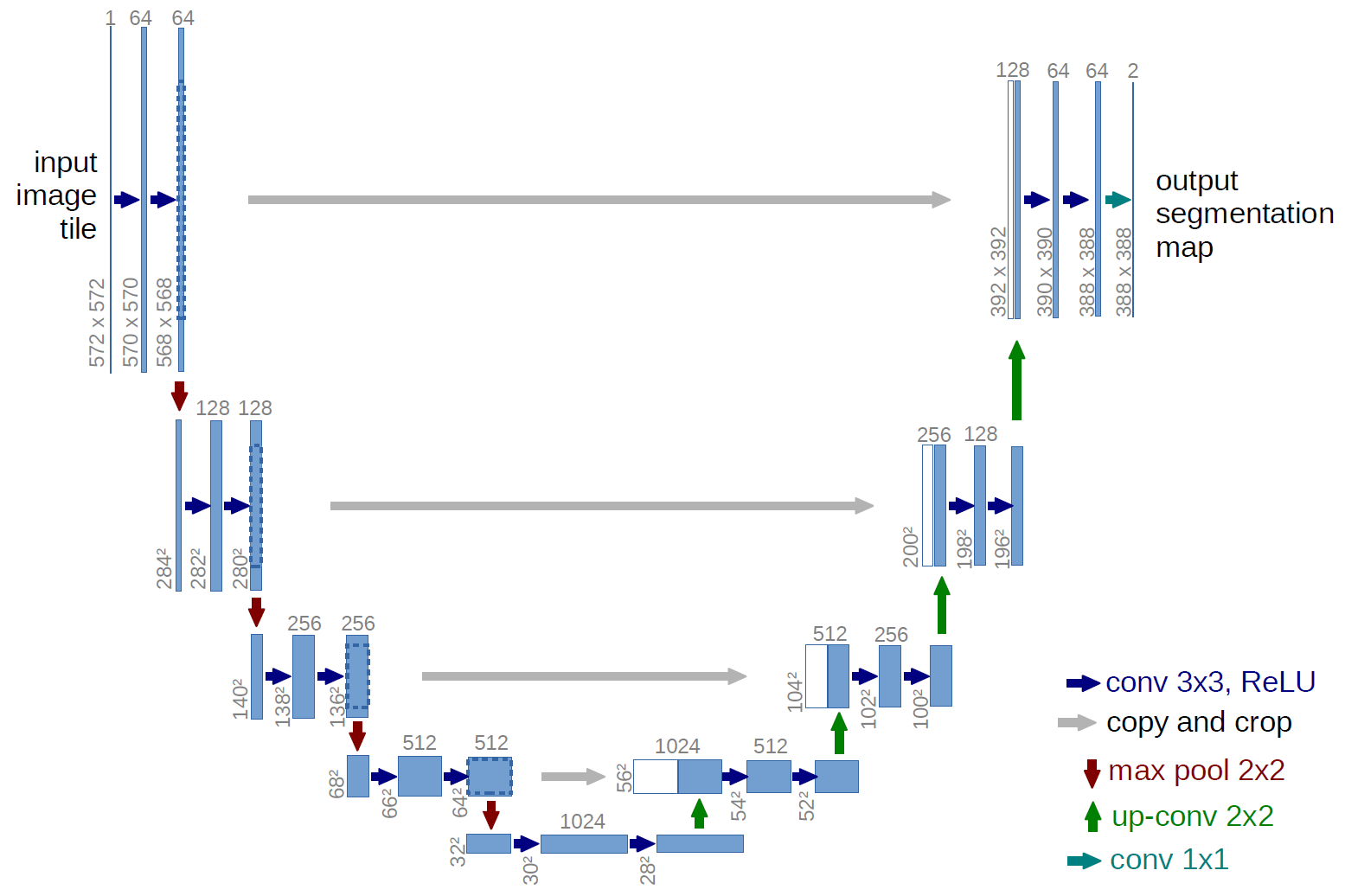
Figure : The U-Net Architecture
- U-Net simply concatenates the encoder feature maps to upsampled feature maps from the decoder at every stage to form a ladder like structure. The network quite resembles Ladder Networks type architecture.
- The architecture by its skip
concatenationconnections allows the decoder at each stage to learn back relevant features that are lost when pooled in the encoder.
U-Net achieved state-of-art results on EM Stacks dataset which contained only 30 densely annoted medical images and other medical image datasets and was later extended to a 3D version 3D-U-Net. While U-Net was initally published for bio-medical segmentation, the utility of the network and its capacity to learn from very little data, it has found use in several other fields satellite image segmentation and also has been part of winning solutions of many kaggle contests on medical image segmentation.
| 2016 | The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation | Arxiv |
In this paper, we extend DenseNets to deal with the problem of semantic segmentation. We achieve state-of-the-art results on urban scene benchmark datasets such as CamVid and Gatech, without any further post-processing module nor pretraining. Moreover, due to smart construction of the model, our approach has much less parameters than currently published best entries for these datasets.
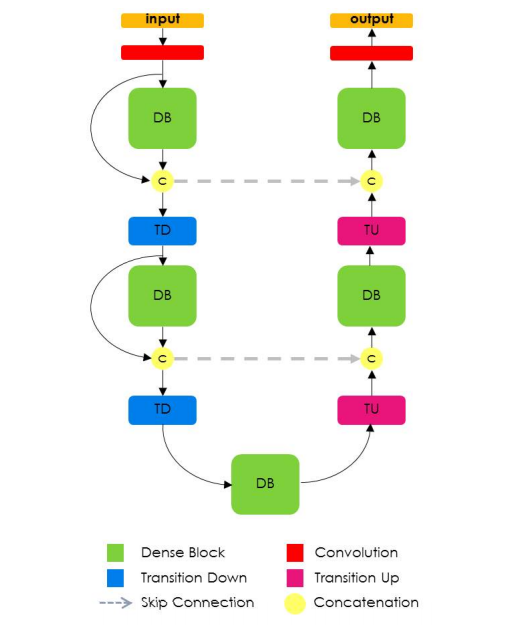
Figure : The Fully Convolutional DenseNet Architecture
Fully Convolutional DenseNet uses a DenseNet as it’s base encoder and also in a fashion similar to U-Net concatenates features from encoder and decoder at each rung.
| 2016 | ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation | Arxiv |
| 2017 | LinkNet: Feature Forwarding: Exploiting Encoder Representations for Efficient Semantic Segmentation | Blog |
In this paper, we propose a novel deep neural network architecture named ENet (efficient neural network), created specifically for tasks requiring low latency operation. ENet is up to 18× faster, requires 75× less FLOPs, has 79× less parameters, and provides similar or better accuracy to existing models. We have tested it on CamVid, Cityscapes and SUN datasets and report on comparisons with existing state-of-the-art methods, and the trade-offs between accuracy and processing time of a network
LinkNet can process an input image of resolution 1280x720 on TX1 and Titan X at a rate of 2 fps and 19 fps respectively
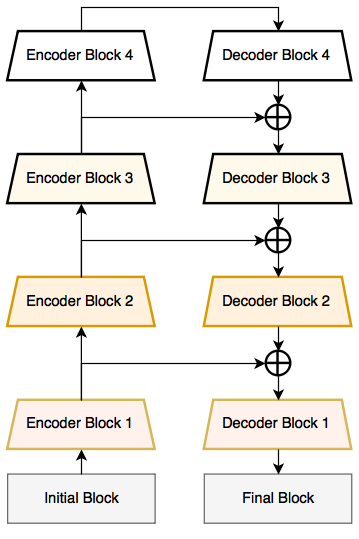
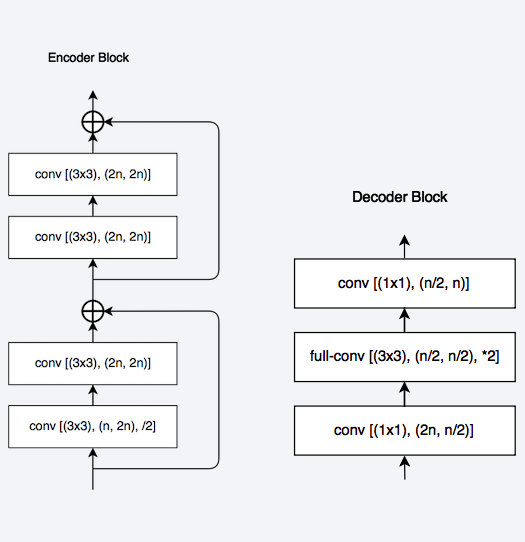
Left : The LinkNet Architecture Right : The encoder and decoder blocks used in LinkNet
The LinkNet Architecture resembles a ladder network architecture where feature maps from the encoder (laterals) are summed with the upsampled feature maps from the decoder (verticals). Also note that the decoder block consists of considerable less parameters due to it’s channel reduction scheme. A feature map with shape [H, W, n_channels] is first convolved with a 1*1 kernel to get a feature map with shape [H, W, n_channels / 4 ] and then a deconvolution takes it to [2*H, 2*W, n_channels / 4 ] a final 1*1 kernel convolution to take it to [2*H, 2*W, n_channels / 2 ]. Thus the decoder block fewer parameters due to this channel reduction scheme. These networks, while being considerably close to state-the-art accuracy, can perform segmentation in real-time on embedded GPUs.
| 2017 | Mask R-CNN | Arxiv |
The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without tricks, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners.
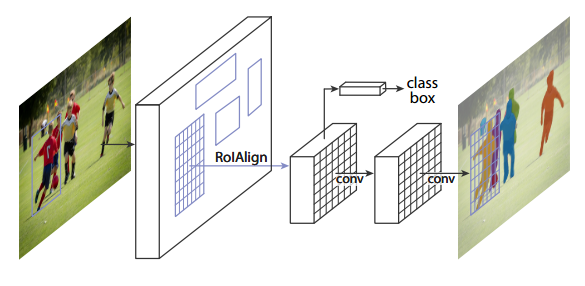
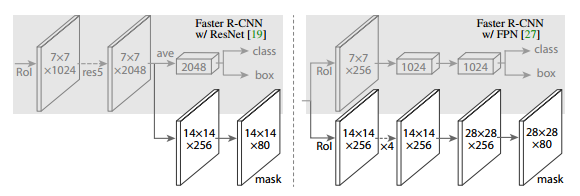
Top : The Mask R-CNN Segmentation Pipeline
Bottom : The auxillary segmentation branch in addition to original Faster-RCNN architecture
The Mask R-CNN architecture is fairly simple, it an extension of popular Faster R-CNN architecture with requisite changes made to perform semantic segmentation.
Some Key features of this architecture are:
- Faster R-CNN with an auxillary branch to perform semantic segmentation.
- The RoIPool operation used for attending to each instance, has been modified to RoIAlign which avoids spatial quantization for feature extraction since keeping spatial-features intact in the highest resolution possible is important for semantic segmentation.
- Mask R-CNN was combined with Feature Pyramid Networks (which performs pyramid pooling of features in a style similar to PSPNet ) achieves state-of-the-art results on MS COCO dataset.
There is no working implementation of Mask R-CNN available online as of 01-06-2017 and it has not been benchmarked on Pascal VOC, but the segmentation masks as shown the paper look very close to ground truth.
| CVPR 2017 | PSPNet: Pyramid Scene Parsing Network | Arxiv |
In this paper, we exploit the capability of global context information by different-regionbased context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet). Our global prior representation is effective to produce good quality results on the scene parsing task, while PSPNet provides a superior framework for pixellevel prediction. The proposed approach achieves state-ofthe-art performance on various datasets. It came first in ImageNet scene parsing challenge 2016, PASCAL VOC 2012 benchmark and Cityscapes benchmark.
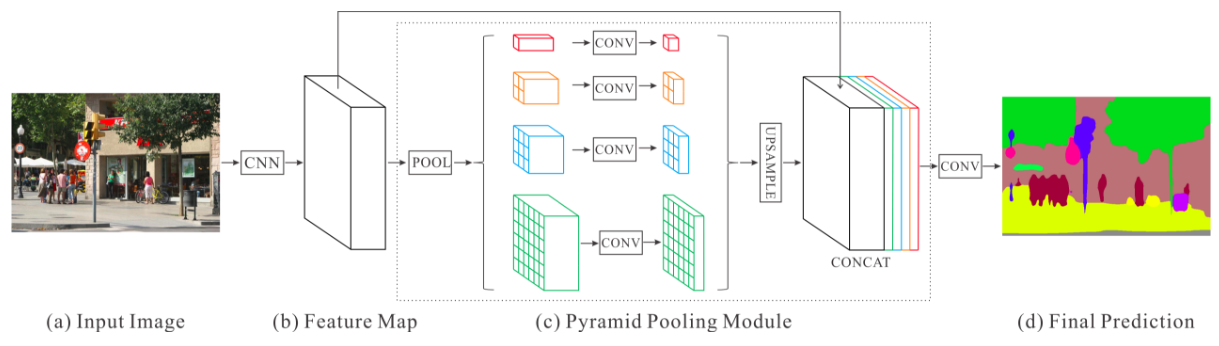
Top : The PSPNet Architecture
Bottom : The Spatial Pyramid Pooling in visualized in detail using netscope
Some Key features of this architecture are:
- PSPNet modifies the base ResNet architecture by incorporating dilated convolutions and the features, after the inital pooling, is processed at the same resolution (
1/4thof the original image input) throughout the encoder network until it reaches the spatial pooling module. - Introcution of auxillary loss at intermediate layers of the ResNet to optimize learning overall learning.
- Spatial Pyramid Pooling at the top of the modified ResNet encoder to aggregate global context.
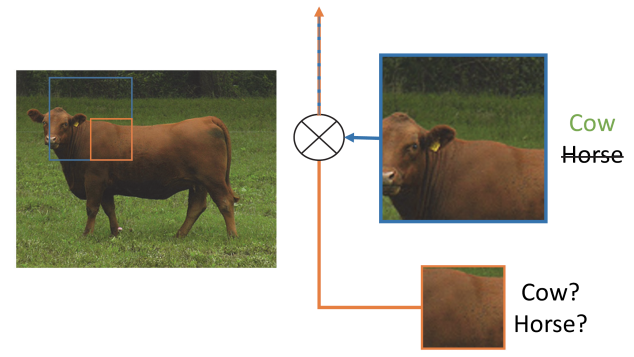
Figure : An illustration to showcase the importance of global spatial context for semantic segmentation. It shows the relationship between receptive field and size across layers. In this case, the larger and more discriminative receptive (blue) maybe of importance in refining the representation carried by an earlier layer (orange) to resolve ambiguity.
The PSPNet architecture is currently the state-of-the-art in CityScapes, ADE20K and Pascal VOC 2012 (without MS COCO training data unlike most other methods). A full visualisation of the network in netscope can be found here.
| CVPR 2017 | RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation | Arxiv |
Here, we present RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections. In this way, the deeper layers that capture high-level semantic features can be directly refined using fine-grained features from earlier convolutions. The individual components of RefineNet employ residual connections following the identity mapping mindset, which allows for effective end-to-end training.
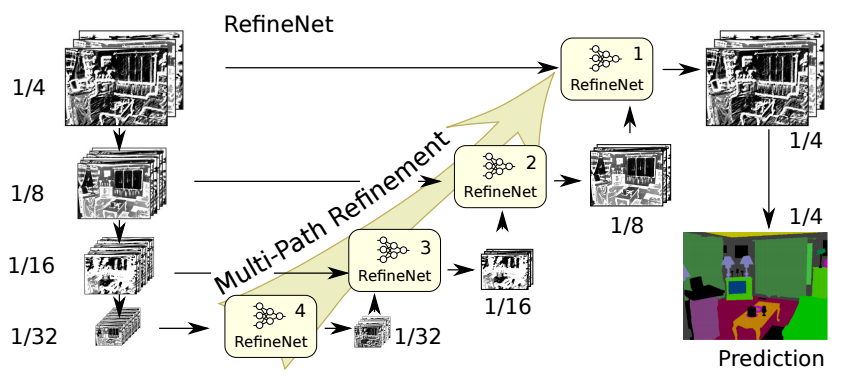
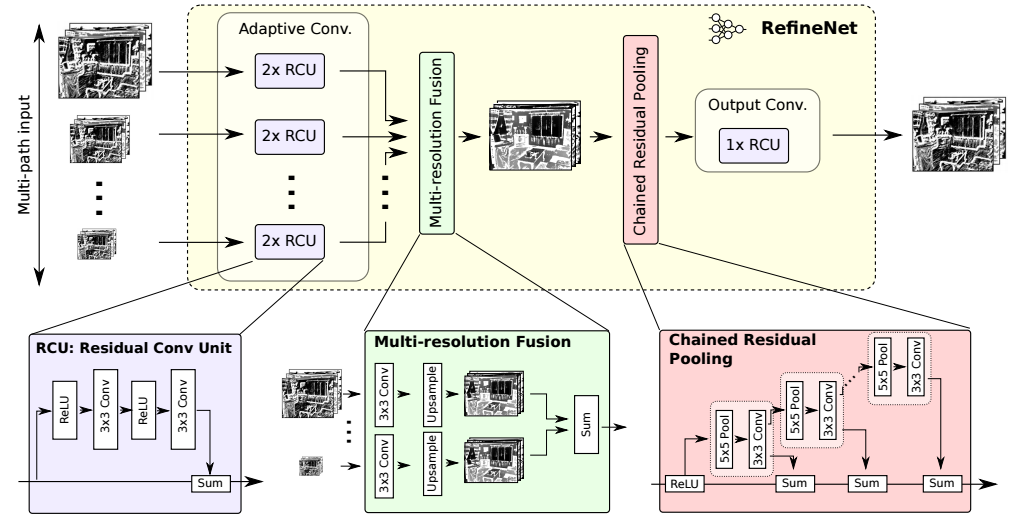
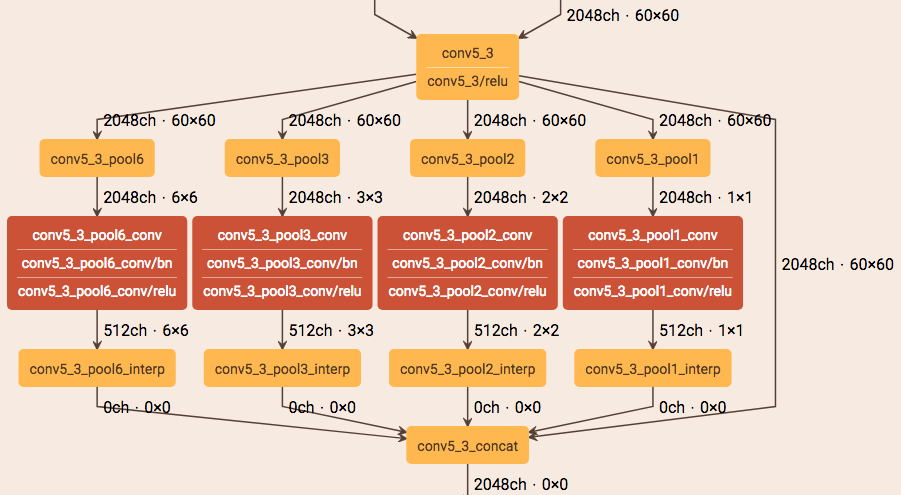
Top : The RefineNet Architecture
Bottom : Building Blocks of RefineNet - Residual Conv Units, Multiresolution Fusion and Chained Residual Pooling.
RefineNet approaches the problem of spatial resolution reduction in conventional convnets in a manner very different to PSPNet (which uses computationally expensive dilated convolutions). The proposed achitecture iteratively pools features increasing resolutions using special RefineNet blocks for several ranges of resolutions and finally produces a high resolution segmentation map.
Some features of this architecture are:
- Uses inputs at multiple resolutions, fuses the extracted features and passes them to the next stage.
- Introduces Chained Residual Pooling which is able to capture background context from a large image region. It does so by efficiently pooling features with multiple window sizes and fusing them together with residual connections and learnable weights
- All feature fusion is done using
sum(ResNet style) to allow end-to-end training. - Uses vanilla ResNet style residual layers without expensive dilated convolutions
| CVPR 2017 | G-FRNet: Gated Feedback Refinement Network for Dense Image Labeling | Arxiv |
In this paper we propose Gated Feedback Refinement Network (G-FRNet), an end-to-end deep learning framework for dense labeling tasks that addresses this limitation of existing methods. Initially, GFRNet makes a coarse prediction and then it progressively refines the details by efficiently integrating local and global contextual information during the refinement stages. We introduce gate units that control the information passed forward in order to filter out ambiguity.
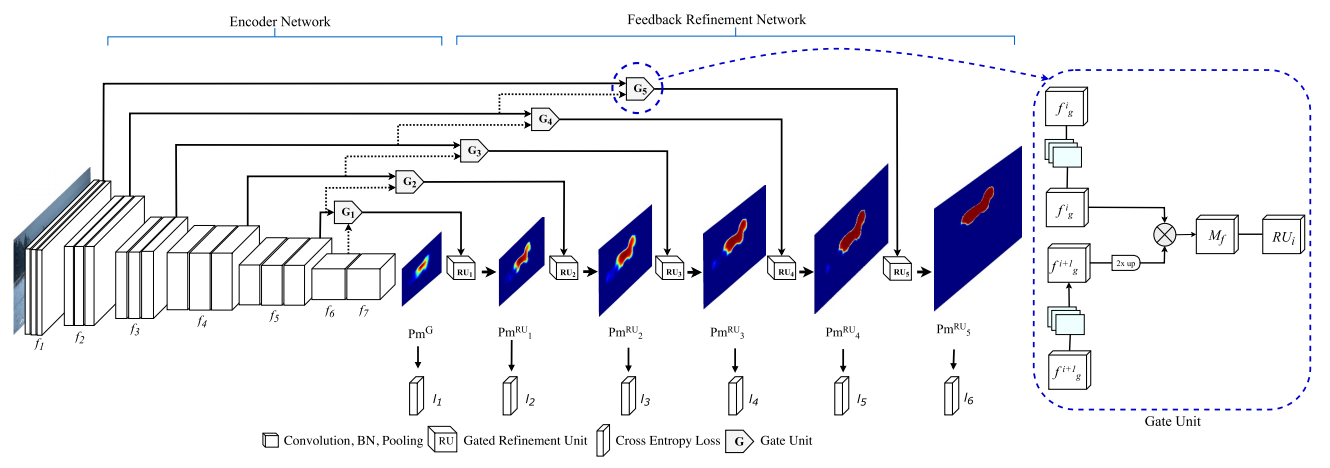
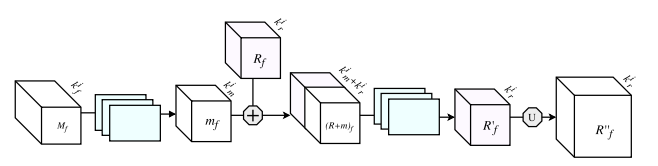
Top : The G-FRNet Architecture
Bottom : The Gated Refinement Unit
Most architectures above rely on simple feature passing from encoder to decoder using concatenation, unpooling or simple sum. However, The information that flows from higher resolution ( less discrimnative ) layers in the encoder to the corresponding upsampled feature maps in the decoder may or may not be of utility for segmentation. Gating the information flow from the encoder to the decoder at each stage using Gated Refinement Feedback Units can assist the decoder in resolving ambiguities and forming more relevant gated spatial context.
On a side note - The experiments in this paper reveal that ResNet is a far superior encoder base than VGG16 for semantic segmentation tasks. Something which I wasn’t able to find in any of the previous papers.
Semi-Supervised Semantic Segmentation
| NIPS 2015 | Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation | Arxiv |
Contrary to existing approaches posing semantic segmentation as a single task of region-based classifi- cation, our algorithm decouples classification and segmentation, and learns a separate network for each task. In this architecture, labels associated with an image are identified by classification network, and binary segmentation is subsequently performed for each identified label in segmentation network. It facilitates to reduce search space for segmentation effectively by exploiting class-specific activation maps obtained from bridging layers.
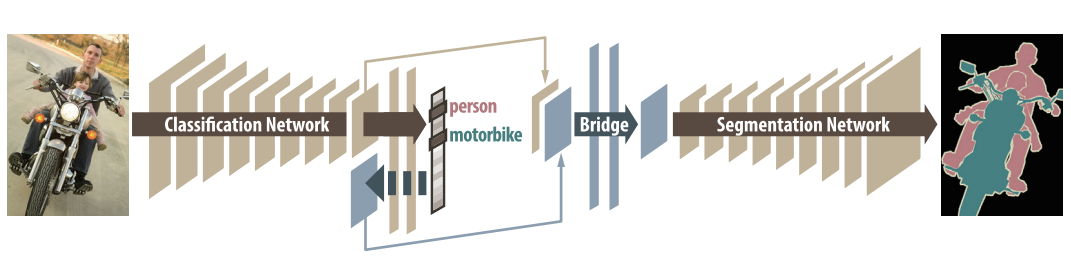
Figure : The DecoupledNet Architecture
This was perhaps the first semi-supervised approach for semantic segmentation using fully convolutional networks.
Some sailent features of this approach are:
- Decouples the classification and the segmentation tasks, thus enabling pre-trained classification networks to be plugged and played.
- Bridge Layers between the classification and segmentation networks produces class-sailent feature map (for class
k) which are then used by the segmentation network to produce a binary segmentation map (for classk) - This method however needs k passes to segment k classes in an image.
| 2017 | Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network | Arxiv |
In particular, we propose a semi-supervised framework ,based on Generative Adversarial Networks (GANs), which consists of a generator network to provide extra training examples to a multi-class classifier, acting as discriminator in the GAN framework, that assigns sample a label y from the K possible classes or marks it as a fake sample (extra class). To ensure higher quality of generated images for GANs with consequent improved pixel classification, we extend the above framework by adding weakly annotated data, i.e., we provide class level information to the generator.
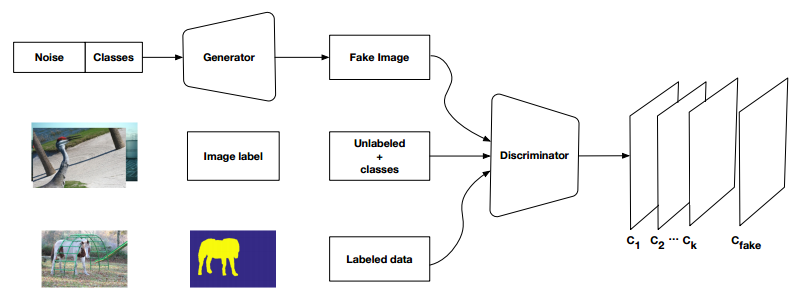
Figure : Weekly Supervised (Class level labels) GAN
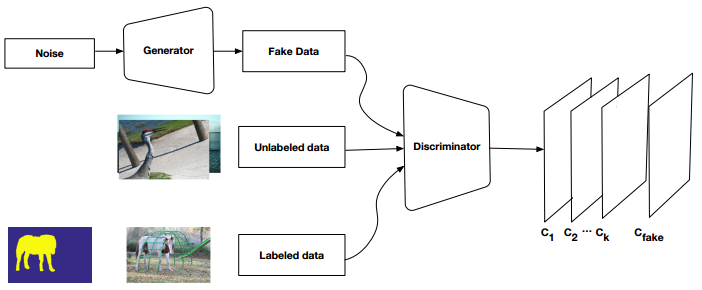
Figure : Semi-Supervised GAN
Datasets
| Dataset | Training | Testing | #Classes |
|---|---|---|---|
| CamVid | 468 | 233 | 11 |
| PascalVOC 2012 | 9963 | 1447 | 20 |
| NYUDv2 | 795 | 645 | 40 |
| Cityscapes | 2975 | 500 | 19 |
| Sun-RGBD | 10355 | 2860 | 37 |
| MS COCO ‘15 | 80000 | 40000 | 80 |
| ADE20K | 20210 | 2000 | 150 |
Results












Figure : Sample semantic segmentation maps generated by FCN-8s ( trained using pytorch-semseg repository) overlayed on the input images from Pascal VOC validation set


Figure: The boat and myself segmented, Alongside Neva River
Debugging
In case this doesn’t work for you, or if there is a mistake/typo, open up an issue in the repo or feel free to shoot a mail.